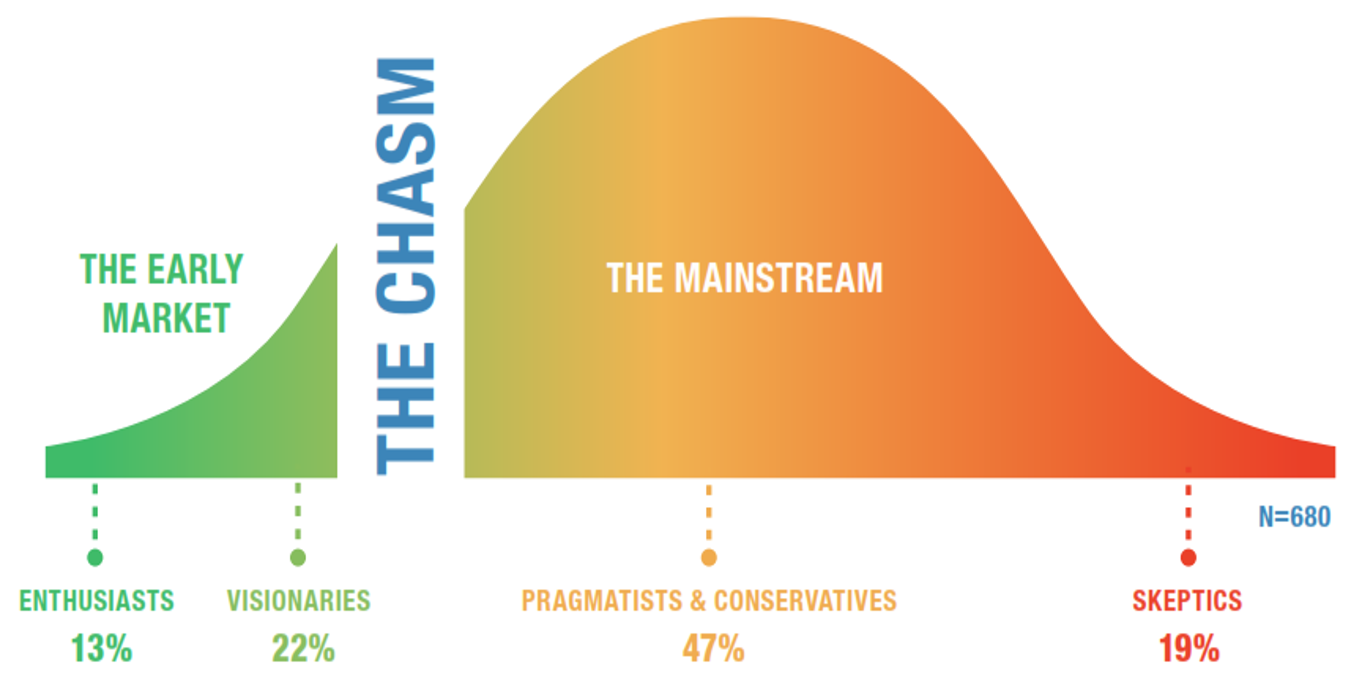
 Recent LNS Research survey results have shown that the Industrial Internet of Things (IIoT) is at the tipping point on the technology adoption curve; with 34% of companies either currently adopting or planning to adopt IIoT technology in the next year.
Recent LNS Research survey results have shown that the Industrial Internet of Things (IIoT) is at the tipping point on the technology adoption curve; with 34% of companies either currently adopting or planning to adopt IIoT technology in the next year.
In consumer markets, the Internet of Things (IoT) has already disrupted incumbents; with Uber, Airbnb, and Nest being commonly cited $1B+ examples. In the industrial space, it is not as clear where and how quickly disruption will occur. There are a number of reasons why disruption will likely not occur as quickly; including asset and technology refresh rates. These rates continue to be measured in decades, not years, and solution selection processes that are measured in months, not minutes.
Even so, one area of the industrial software landscape that many believe is ripe for disruption is the Data Historian. In this post we will examine how the Data Historian has evolved to date, why it is ripe for disruption, where it is likely to go in the future, and what this means for vendors and end users.
Evolution of Plant to Enterprise Data Historian
The Data Historian emerged out of the process industries in the early 1980’s as an efficient way to collect and store time series data from production. Traditionally, values like temperature, pressure, and flow among others are associated with physical assets, time stamped, compressed, and stored as “tags.” This data was then available for analysis, reporting, and regulatory purposes in the future.
Given the amount of data generated, a modest 5,000 tag installation that captures data on a per second basis can generate one Terabyte per year. Proprietary systems have proven superior to open relational databases, and the Data Historian market has grown continually over the past 35+ years. Over this time, Data Historians have expanded into many different industries and applications where time series data is prevalent. Data Historians have also moved from single site, on-premise implementations to multi-site cloud based implementations that role data up to a single view. There has also been the emergence of an ecosystem of System Integrators and software providers to implement these systems and create value added applications on-top of Data Historians.
For all these reasons, the future may seem very bright for the Data Historian market, but there is disruption coming in the form of IIoT and Industrial Big Data Analytics.
Who Does the Enterprise Data Historian Drive Value for?
Despite the best efforts of many leading Data Historian vendors, the main users of these systems has not significantly expanded beyond the process engineers that the systems were originally designed for. In essence, those that care about and are responsible for the associated processes are the ones using the system. As these systems have been rolled up from asset or plant specific applications to enterprise applications, the main use cases have slightly expanded but generally remained the same.
For example, a corporate process engineer today may use an enterprise level Data Historian to compare how heat exchangers perform across plants or historize regulatory emissions data across the enterprise; where as previously it was only possible for local plant engineers to track this information locally. Although there is undisputed incremental value associated with enterprise level Data Historians, it is well short of the promise of IIoT and Industrial Big Data Analytics.
In an IIoT world, time-series heat exchanger and emissions data is just one type of data. It is being used in conjunction with structured transactional business system data and unstructured real world data. This is to deliver next-generation analytics and applications in a focused use case like energy and emissions optimization.
In our recent post on Big Data Analytics in manufacturing I argued that Big Data is just one component of the IIoT Platform, and that volume and velocity are just two components of Big Data. The other (and most important) component of Big Data is variety; making the three types structured, unstructured, and semi-structured. In this view of the world, the Data Historians provides volume and velocity but not variety.
If Data Historian vendors want to avoid disruption, expand the user base, and deliver on the promise of IIoT use cases, solutions must bring together all three types of data into a single environment that can drive next-generation applications that span the value chain.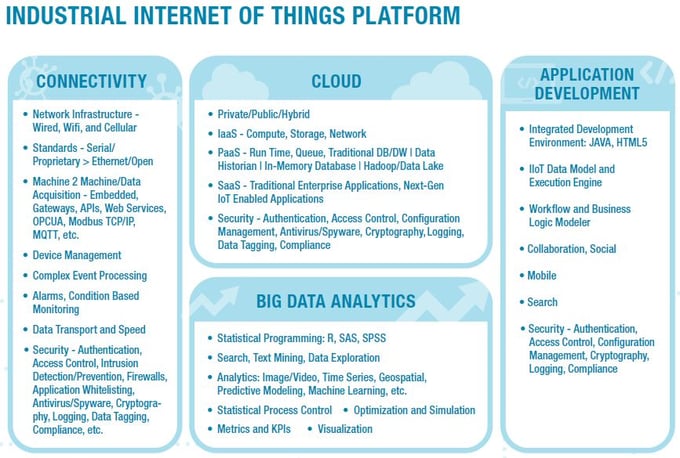
Pricing Models Issues with Tags in a Cheap Sensor World
If not only tacitly, the tag pricing model used by most Data Historian vendors is tied to the i/o pricing model used by automation vendors (often the same company). For example, the Data Historian tag price is often 5%-10% of the i/o price. In an IIoT world, there are several issues with this model that may lead to disruption.
First, disruptive companies in adjacent industries charge by volume of data, not by number of data sources. Take for example the Big Data platform Splunk, which started by collecting log file information from IT servers. It doesn’t matter how many servers Splunk collects data from, it only matters how much data is coming into the system, which of course is the logical way to build a pricing model when data collection is done wirelessly and data storage is done with the cloud.
Second, in today’s industrial landscape, almost all process data is collected through control systems, so it has made sense for Data Historian pricing models to be connected to the automation systems’. In the future, as cheap sensors and IIoT gateways come to market and extend the data collection capabilities of automation systems, there will be many new data sources. Those sources could feed Data Historians considerable cheaper than traditional control technologies. We are not too far from a scenario where the incremental costs of adding IIoT enabled wireless sensors and gateways will be orders of magnitudes cheaper than adding the requisite Data Historian tags, obviously an untenable situation.
Data Historian is a Significant Piece of the IIoT and Big Data Story
To answer the question posed in the title of this post, it is unlikely that the Data Historian will die any time soon. It is, however, highly likely that disruption is coming, making the real question two-fold:
- Will the Data Historian be a central component of the IIoT and Big Data story?
- Which type of vendor is best positioned to capture future growth: traditional pure play Data Historian provider, traditional automation provider with Data Historian offerings, or disruptive IIoT provider?
If the Data Historian is going to take a leadership role in the IIoT platform and meet the needs of end users, providers in the space will have to develop next-generation solutions that address the following:
- How to provide a big data solution that goes beyond semi-structured time series data and includes structured transactional system data and unstructured web and machine data.
- How to transition to a business/pricing model that is viable in a cheap sensor, ubiquitous connectivity, and cheap storage world.
- How to enable next generation enterprise applications that expand the user base from process engineers.
And, if it is a traditional vendor (pure play or automation) that succeeds in delivering a successful next-gen solution, the company must be willing to disrupt existing cash cows (highly profitable software or hardware offerings) and extend outside of its traditional comfort zone (time series data and control applications). Both of which are huge asks considering the conservative nature of the industry.
But it is not impossible given the incentives provided by the financial momentum some disruptors have (Splunk in 7 years has more revenue than OSISoft in 35) and the executive focus some early mover traditional incumbents have (GE CEO Jeff Immelt has bet Billions on IIoT and Big Data Analytics with the GE Digital re-org).
Gain a year of free access to new research in our IoT Research Library by completing a survey.
