Some of the most frequently asked questions LNS Research receives when clients are planning to scale in Industrial Transformation (IX) are concerned with DataOps and data contextualization.
While this author is not an IT architect nor a data scientist, I think we can get a common sense handle on the subjects to guide customers and properly position solutions available in the market. Here are my thoughts relative to the challenges at hand. I won’t cover every possible detail here, so look for future research on this subject. Let’s start with some basic definitions.
Several sources define DataOps primarily from an IT perspective. Here are four such definitions:
So I think we all get the idea. Now comes the context of industrial. Here we have to remember that we deal with multiple data types: structured, unstructured, and semi-structured (time series fits here). And unlike the two-dimensional deterministic data found in most industries, industrial data can have uncertainty, noise, multi-dimensionality, and a host of other problems that make it very challenging to organize it in a meaningful way so it can be consumed. So, remember the four Vs of big data… volume, variety, velocity, and veracity... actually, it’s five Vs with value being the fifth. But hold the thought that only big data needs organization.
These models are used for various purposes. In our case, we are most interested in hierarchical, object-oriented, semantic, and entity-relationship models. We also recall that early process historians used relational databases to store data but ran into speed, granularity, and scalability limitations. Hence, they were replaced by newer platforms designed for time-series data, such as the well-known AVEVA PI System. Today’s RDBMS is much more capable, but we still use dedicated time series historians for superior performance and other capabilities.
Remember also that we are not just talking about time-series data or hierarchical asset data. Models can include other information such as time, events, alarms, units of work, units of production time, materials and material flows, and people. This becomes especially important when we address Level 3 applications like MES/MOM and OPM/EPM, where legacy solutions have rigid data structures that differ by vendor despite common functionalities. There are no standards yet for these models, although the Clean Energy Smart Manufacturing Institute (CESMII) has begun to address them. As new forms of manufacturing systems emerge, forming more flexible and agile relationships will be very important.
Why Data Contextualization is so important
In computer science, contextualization is the process of identifying the data relevant to an entity (e.g. a person, place, or thing) based on the entity's contextual information. In simple terms, contextualization is a way of relating raw data from sources into a format associated with an entity so that others can easily consume it, others often meaning analytics applications. The key is arranging the data in the way that the consumer wants it.
Contextualization in a broader sense includes conditioning the source data, organizing it to persist and synchronize as source data changes, and finally, putting it in format for consumption by whatever application needs it. The term used to describe a set of data that describes and gives information about other data is metadata. Think of metadata as the data glue.
Why is metadata important? We have all seen the diagrams showing multiple applications connected to multiple data sources via APIs - the spaghetti architecture. Metadata unties the knots, simplifies connectivity, and maintains order. Sometimes the term data model is used to describe a particular metadata structure. For example, one may have a data model of a pump, which describes all the data about the pump, including time-series data like pressure, flow, temperature, amperage, etc. However, keep in mind that most applications are not designed to consume multiple data model types. This would make architecting them messy, to say the least. Thus, the metadata approach makes it easier to handshake with the data needed.
Where can you and should you contextualize data?
Now we get to the good questions. When considering the operational data lake in the diagram below, we often think of contextualizing all varying data types in the Cloud. But contextualization isn’t just limited to the Cloud. In fact, we can and should contextualize it at the Edge as well as on-premise. We are all familiar with the most common contextualization on-premise, that of the asset tag hierarchy that we find in control systems and reflected again in historians. This hierarchy is based on the S95 model of enterprise, plant, area, unit/line/cell, equipment, device, control module, etc. S95 recently added a model for material flow, though its uptake has been limited.
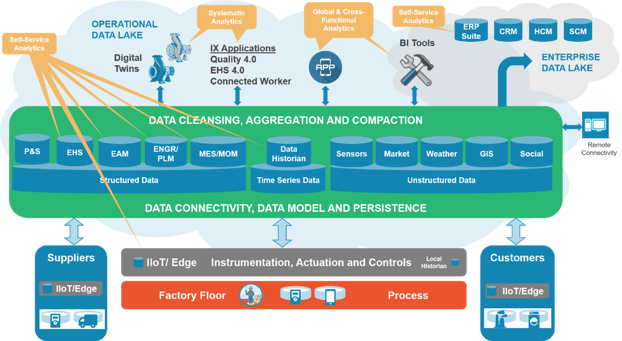 Figure 1 - The Operational Data Lake
Figure 1 - The Operational Data Lake
So, where should we contextualize? Well, one can contextualize at the control system and historian level. This is the common ISA 95 tag-based asset hierarchy so familiar to all of us. Here we see OPC UA, which has organized attributes – effectively, a data model. In fact, OPC UA defines a generic object model, including the associated type system. In addition to this data model, rules have been defined to describe how to transform every physical system into a model conforming with OPC UA to represent it in an OPC UA server. Every kind of device, function, and system information can be described using this meta-model. The base type system supports relationships between objects, so-called references, as well as multiple inheritances. Thus, it can be compared to a modern object-oriented programming language. The base model provides object and variable types as well as reference and data types. Based on this model, OPC UA can represent every kind of data, including its metadata and semantics. This is why OPC UA is good for handling the typical attributes of process data, plus events and alarms. Unfortunately, as of this writing there is no standard for data modeling the attributes in OPC UA. Most analytics solutions at the plant level tap the time series tag structure directly. But there’s more data needed than just time series. And integrating vibration data can also be problematic.
Next, we can contextualize at the Edge, also with object data models. Some use MQTT to pass the data along to the Cloud. MQTT originally did not have a model, but with the addition of Sparkplug, bingo, we are now good. AMQP is another option. I won’t get into a discussion of AMQP or MQTT with Sparkplug vs. OPC UA. Keep in mind that with IIoT, we can take sensor data directly to the Edge or the Cloud, completely bypassing the control systems.
Finally, at the Cloud level, where many scaled applications will run, we need even more sophisticated contextualization to handle all of the varied data types and sources that you see in Figure 1. A question worth asking is, “Do we need all the source data in its native granularity in the Cloud?” Vendors have attacked the contextualization challenge with the tag-based models, semantic models, object models, and knowledge graphs (KGs), and in some cases, added graph databases. LNS Research believes that using knowledge graphs is the superior approach but that all approaches can work. The main drawback to a hierarchical model is that it can have only one-to-many relationships between nodes, while other methods can have many to many relationships. Some vendors embracing semantic and object models usually offer pre-defined models, often leveraging the ISA 95 asset hierarchy along with additional pre-defined relationships. I will leave the detailed pros and cons to future publications.

Now one question is what to do at the Edge. Let’s say an analytics model is built in the Cloud then will be run at the Edge. Do we need to get the data from the Cloud, or just tap the Edge data model? I would think yes, the Edge data model, if the data at that point is what the analytics app needs. No doubt there will be many uses cases where we should run at Edge vs. Cloud. And, of course, each layer should be able to absorb the lower layers models. So if you have, for example, an Edge data model and send it to the Cloud, it can be incorporated into the metadata structure in the operational data lake. Note that some vendors can upload the PI Asset Framework (AF) models. Thus, the architectural approach is for each layer not to compete but to complement each other. Ideally, all of these data models would synchronize.
Lastly, because this has been an open issue, many analytic apps do their own contextualization because data wrangling used to be 75% of an analytics project’s effort. Either way, data has to be put into a format for easy consumption.
Major Players
Suffice it to say, there are a host of players in this space. They include:
Infrastructure is a new category where LNS Research places vendors addressing key components of the DataOps architecture but don’t provide a complete solution by themselves. Most of these vendors are startups.
In considering the vendor landscape, it is important to remember a couple of caveats. First, a time series database is not a historian. Historians have far more functionality, and their place on-premise is highly valuable and secure. Second, just having a database doesn’t mean you have or will get a fit-for-your-purpose data model, let alone a metadata structure to go along with it, especially one designed for handling IT and OT data. This is especially true for the database vendors and the hyperscalers. Obviously, IT can DIY and build one or combine a database with an infrastructure component. Some of the automation vendors use third-party solutions, while most have or are building their own.
Where to go from here
So, where does this leave us? Well, it leaves us smack dab in the world of the New OT Ecosystem, as shown in Figure 2. Architecting the OT Ecosystem is more complex than past layered architectures and will require IT and OT to work together. Data governance is critical, and new roles, like data engineers, will need to be created. Careful consideration and analysis of who needs what data, where, and when, and for what purpose will help drive the answers to the contextualization question.
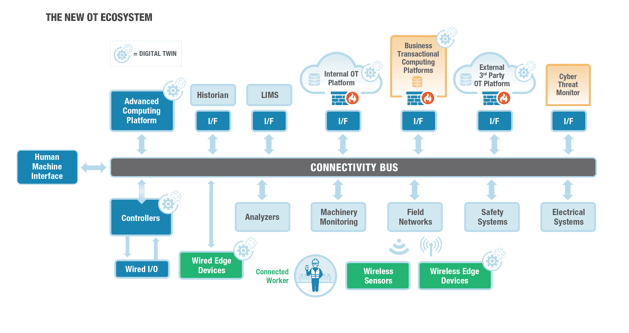 Figure 2 - The New OT Ecosystem
Figure 2 - The New OT Ecosystem
We hope that this blog helps clarify the contextualization issue without being highly technical. We hope that this generates discussion and a greater understanding of IT and OT data management challenges. Future publications will delve into the issues in more depth and shed additional light on just which path vendors and end-users should take and the pros and cons of those directions.

All entries in this Industrial Transformation blog represent the opinions of the authors based on their industry experience and their view of the information collected using the methods described in our Research Integrity. All product and company names are trademarks™ or registered® trademarks of their respective holders. Use of them does not imply any affiliation with or endorsement by them.


