In my last blog on Data Contextualization, we talked about data contextualization at various levels in the OT Ecosystem architecture, particularly in the Operational Data Lake. LNS Research is increasingly hearing the term “Data Hub” used to describe the processing, conditioning, contextualization, persistence, and access functionality so key to data management and one’s ability to scale the New OT Ecosystem. Questions we frequently hear are:
-
“Are Data Lakes and Data Hubs the same thing?”
-
“If not, then do they have to be combined as shown in the green section of Figure 1 below?”
-
Is a Unified Namespace the same thing as a Data Hub?
-
What the heck is a Unified Namespace anyway?
While I am not an IT architect, my intention is to get a common sense handle on the subjects to guide customers and properly position solutions available in the market. I won’t cover every possible technical detail here, but hopefully, my approach will make sense, especially to OT people who must increasingly live in an OT world full of IT. Let’s start with some basic definitions.
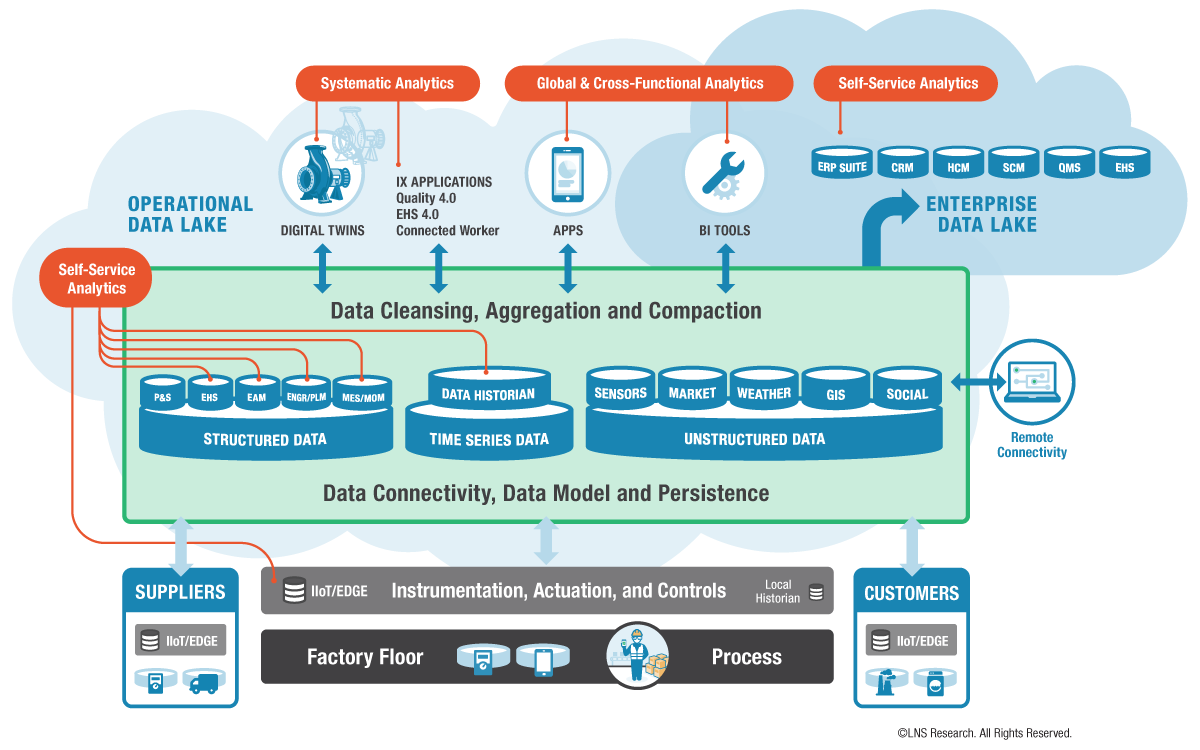
Figure 1 - The Operational Data Lake
Data Terms
In my last blog, I referenced several similar definitions for DataOps, which primarily has to do with data management for analytics. There are a few more terms that need to be addressed, again allowing for some variance in definition depending on who is doing the defining:
Data Lake: A large body of usually raw data in one physical location (e.g., object storage in the Cloud)
Data Mesh: A pattern for defining how organizations can organize around data domains, focusing on delivering data as a product.
Data Fabric: An architecture and set of data services that provide consistent capabilities across multiple endpoints spanning hybrid, multi-cloud environments. It standardizes data management practices and practicalities across Cloud, on-premises, and Edge devices. Data Fabrics essentially add a semantic layer to data lakes to smooth the process of modeling data infrastructure, reliability, and governance.
Sematic Layer: A semantic layer is a representation of data that helps end-users access data autonomously using common terms.
Data Swamp: Data stored without organization and precise metadata to make retrieval easy, i.e., an unstructured, ungoverned, and out of control Data Lake where due to a lack of process, standards, and governance, data is hard to find, hard to use, and is consumed out of context. In short, the reason why we have Data Hubs.
Unified Namespace (UNS): A Hub and Spoke model where the hub acts as a central repository, allowing connections to Edge devices and other platforms and databases (the spokes), decreasing the number of separate connections that must be maintained. In essence, the hub of this Hub and Spoke model is a form of the Data Hub.

If these terms leave you more confused than when you started reading, join the club. I am an OT guy, and so much of this was new to me. And it’s another reason to have a good IT/OT architect on your team. The bottom line is that these terms support the various perspectives that must be addressed in connecting and delivering data, from architecture and patterns to services and translation layers. Remember, we are not just talking about time-series or hierarchical asset data. Data such as time, events, alarms, units of work, units of production time, materials and material flows, and people can all be contextualized. And this is the tough nut to crack as the new OT Ecosystem operates in multiple modes, not just transactional as we find in the back office.
Data Hub Architectures
So, how does one assemble a Data Hub? First, let’s talk about what goes on in the Data Hub, then we’ll talk about where it fits in the OT Ecosystem architecture and the options for components and vendors.
In our first blog, we said that contextualization in a broader sense includes conditioning the source data, organizing it to persist and synchronize as source data changes, and finally, putting it in format for consumption by whatever application needs it.
Thus, we see the Data Hub having the following six core functions:
-
Processing: Handling batch, streaming, and intermittent data simultaneously.
-
Conditioning: Screening, filtering, interpolating, and other data conditioning functions, which may also include the use of Machine Learning and other advanced techniques.
-
Synchronization: Aligning various data types, especially in the time dimension.
-
Contextualization: Creating and storing the relationships between the data, i.e., the data model with its various types.
-
Persistence: Maintaining the relationships as source data changes.
-
Access: Providing access to data consumers in the format they need to consume it. And this usually means supporting bi-directional flow from the consumer through the Data Hub and down to other systems and applications.
All of the above are ideally in a low code/no code environment, which could be part of a larger IX Platform capability. And built on loosely-coupled microservices-based functionalities for metadata, workflow engine, standard and custom visualization, and applications that avoid hard-coded data structures and integrations. Data Hubs need to be flexible.
In addition, some Data Hubs have additional capabilities, including but not limited to:

-
Productized connectivity to many advanced analytics platforms and visualization applications.
-
Pre-packaged applications for various use cases, typically visualization at a minimum.
-
The ability to upload historian asset hierarchies, e.g., AVEVA PI AF
-
The ability to scan P&ID diagrams and capture the tag data and associated attributes.
-
The ability to read so-called Smart P&IDs and capture their data.
-
The ability to overlay data on 3D engineering diagrams.
-
The ability to launch and manipulate external applications, such as advanced analytics and digital twins. This “push” workflow capability can be advantageous because the Data Hub can use programmed times or conditions such as changes in the source data to trigger the external application instead of just having the external application ”pull” the data from the Data Hub.
-
The ability to manipulate robots, cobots, and drones and acquire data from them.
-
The ability to exchange data with the OSDU® platform, including Energistics® data formats like WITSML™. This capability is especially desirable for upstream companies that deal with surface and subsurface data.
-
The ability to extend and customize the platform using Python and other DevOps tools.
*OSDU = Open Subsurface Data Universe™ is a cross-industry collaboration to develop a common, standards-based, and open basis that will bring together exploration and development data. Energistics is a global consortium that facilitates the development of data exchange standards for the upstream oil and gas industry. Both OSDU and Energistics are part of the OpenGroup®, an organization dedicated to developing open standards for the industry.
Clearly, a lot is going on in the Data Hub. Of course, one may not need all the optional functions, or one can use third-party or DIY components to do them, but we always find it’s easier if they are productized and supported.
Now on to the architecture. Figure 2 shows the conceptual OT Ecosystem. The top middle function, the Internal OT Platform, is the Data Hub's primary subject, along with the Edge devices and local on-premise historian. Figure 3 expands the concept by decomposing Figure 1’s green section into the Data Lake and Data Hub. Again, we show them separated because one can acquire them separately or combined depending on the vendor’s offering or how IT chooses to architect the functionality. For example, some operating companies have decided to use a separate Data Lake to store all the source data in its original format, keeping it separate from the Data Hub vendor’s platform and then feeding it to the Data Hub. Note that the separate approach means more components to manage. Also, note that the Data Hub needs a place to store its relationships, apart from the Data Lake, such as in a graph database, though it may also use the Data Lake in the combined arrangement.
Furthermore, the Data Lake may have one or more databases. For example, both time series and NoSQL, depending on how the user wants to store their data. This allows the end-user to choose components from ISVs, database vendors, or hyperscalers who offer time series, SQL, and NoSQL. In the case of combined Data Lake and Data Hub, the advantage is that the vendor takes care of all the internal plumbing. And IT knows that there is always more internal plumbing than the vendor’s as the solution must be fit into the company’s environment. Don’t forget about cybersecurity, either.
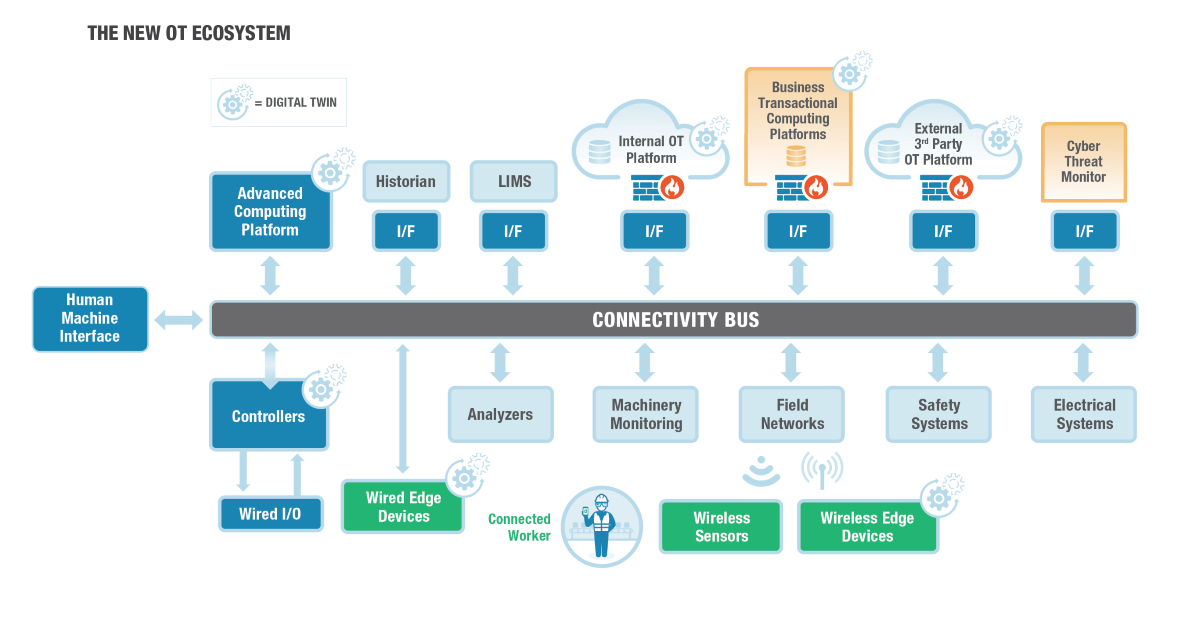
Figure 2 - The New OT Ecosystem
Options Galore
Regarding the options for components and vendors, we have already discussed the types of databases that could be incorporated. And in our last blog, we discussed the various types of data models, be they hierarchical, object-based, or graph-based. Finally, the dotted lines of the multiple data flows are meant to show the options to move data to where it's needed to satisfy the business case and associated decision-making. Contextualization is shown at multiple levels.
The database vendors and hyperscalers don’t yet have comprehensive platforms. But the hyperscalers with the right infrastructure partners could substantially deliver the Data Hub. The key for the hyperscalers is to move from offering a suite of services to assembling them into a domain-relevant solution. It’s nice to show flow diagrams of components, but these don’t constitute a functioning solution. Unfortunately, we don’t see the database vendors doing this as so much of their business is driven by use cases that are not focused on industrial operations. The majority of ISVs and automation vendors are assembling their own Data Hub solutions based on past platforms and their deep domain experience. In some cases, they are using infrastructure vendor components or third-party platforms. And, as we pointed out, some infrastructure vendors concentrate on the core functions for the Cloud or the Edge, while others incorporate the additional functions to varying degrees.
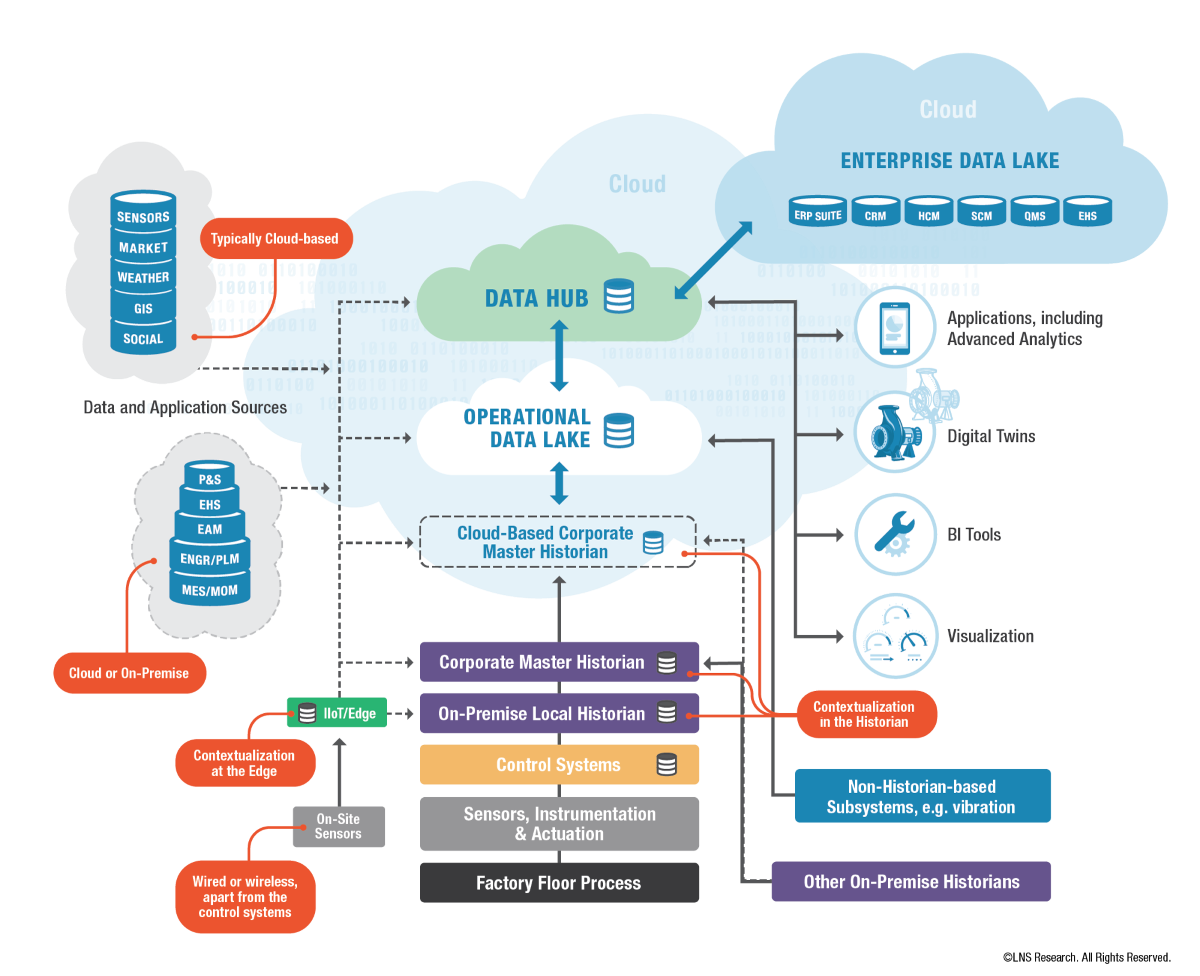
Figure 3 - The Data Hub Concept Expanded
Build vs. Buy
End-users would be wise to explore build vs. buy when architecting the Data Hub. For example, if one builds, does one purchase components and assemble, i.e., you are the productizer and integrator. Or do you DevOps code from scratch? Or does one buy a substantially complete Data Hub platform that meets your requirements? Of course, there are pros and cons to all options, and no solution is perfect and without some additional work to “fit the engine in your automobile.” So end-users put your potential options through the test, be they internal resources with their own design or external supplier's products.
Perhaps the one caution we would advise is thinking that you can convert and scale your traditional historian into a Data Hub. Traditional historians aren't simply designed to do this despite their vital role in storing time-series data. Don’t even let your IT department think they can do this. It’s a primary reason why several vendors are rearchitecting their older solutions, which attempted to glue together different data types, based on the historian asset hierarchy, by APIs and mapping (canonical) techniques, which in large part turned out to be a project, not a product. Make one change to the data relationships, and oh-oh. It’s like pulling one brick out of the wall, and the wall falls down. Hello, more vendor dependency and additional cost. So avoid the road to data perdition.
Wrapping up
So, where does this leave us? Well, LNS Research end-user clients across all our industry verticals report that they have prioritized architecting the Data Hub solution. It is seen as key to data democratization and scaling solutions across the enterprise. But it is still early days in the evolution of Data Hub solutions. This trend is sure to accelerate.
Again, we hope that this blog helps further the understanding of the Data Hub concept. In addition, we hope that this generates discussion and a greater understanding of IT and OT data management challenges. As always, your feedback and comments are most welcome.

All entries in this Industrial Transformation blog represent the opinions of the authors based on their industry experience and their view of the information collected using the methods described in our Research Integrity. All product and company names are trademarks™ or registered® trademarks of their respective holders. Use of them does not imply any affiliation with or endorsement by them.
